LG Electronics 라이프로그 AI 어시스턴트 구축기: 그래프 검색으로 일상을 탐색하다
TL;DR
L사 고객의 라이프로그 데이터를 기반으로, "저번주에 커피 몇 번 마셨더라?" 같은 일상적 질문에 정확히 답변하는 AI 어시스턴트를 구축했습니다. 벡터 검색 + 그래프 탐색의 하이브리드 구조로 Context를 20,000개에서 3,000개로 85% 감소시키면서도, 사용자 요구사항 기반 평가셋에서 92%(74/80개) 정확도를 달성했습니다.
프로젝트 배경
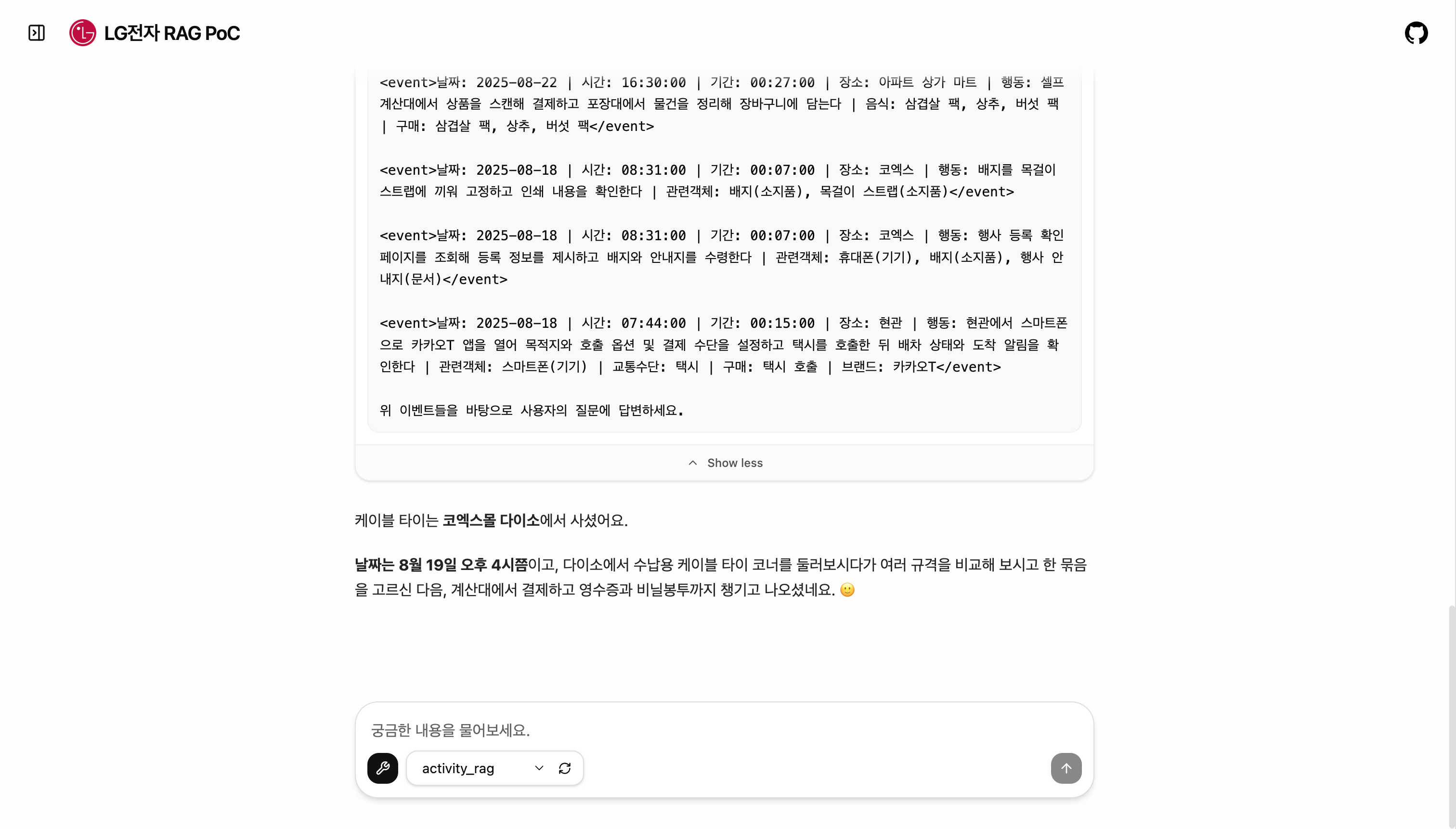
사용자가 "캠핑 갔을 때 쓴 버너 뭐였지?"라고 물으면, AI가 복잡한 활동 기록을 연결해서 정확한 답을 찾아줘야 합니다.
단순 키워드 검색으로는 불가능합니다. 시간·장소·활동·브랜드·음식·상황 사이의 복잡한 연결 구조를 AI가 스스로 이해하고 탐색할 수 있어야 합니다.
핵심 과제 4가지:
- 데이터 양이 많아져도 느려지지 않는 검색
- 구어체·줄임말·외래어도 정확히 이해
- 통계/패턴 관련 질문에도 정확히 답변
- Context 최적화로 효율성과 일관성 동시 달성
기술적 도전과 해결
1. 그래프 기반 검색: 맥락 단위로 찾는 능력
"캠핑에서 썼던 버너 브랜드"라는 질문을 분해하면:
- 활동: 캠핑 → 장소: 캠핑장 → 행동: 요리 → 물건: 버너 → 브랜드: ?
전통적인 벡터 검색만으로는 이 관계 추론이 불가능합니다. 우리는 모든 활동 데이터를 그래프 형태로 재구성했습니다:
- 14개 메타데이터 키: 시간, 위치, 활동, 소비, 개체명 등
- 242개 엣지: 메타데이터 간 연결 관계
- 에이전트가 질문을 분석해 어떤 경로를 따라 탐색해야 하는지 스스로 결정
2. 하이브리드 검색 + 자동 시간 필터링
수천~수만 건의 활동 데이터에서 매번 전체 스캔은 비효율적입니다. 벡터 검색(ChromaDB)과 그래프 탐색을 결합한 하이브리드 구조를 설계했습니다.
특히 자연어 시간 표현 자동 해석이 핵심이었습니다:
- "지난주" → 날짜 범위 자동 계산
- "올해 초" → 1~3월 필터
- "저녁에" → 시간대 필터
LLM이 이런 표현을 해석하여 검색 범위를 자동으로 좁혀줍니다.
3. Context 최적화: 85% 감소, 성능은 유지
초기에는 검색 결과로 20,000개의 Context를 LLM에 전달하고 있었습니다. 비용도 높고, 오히려 불필요한 정보가 답변 품질을 떨어뜨리는 문제가 있었습니다.
그래프 탐색을 통해 관련성 높은 Context만 선별하여 3,000개로 85% 감소시켰고, 오히려 답변 일관성이 향상되었습니다. 적은 정보를 정확히 주는 것이 많은 정보를 던지는 것보다 낫다는 교훈을 얻었습니다.
4. 한국어 자연어 처리 최적화
한국어의 다양한 표현 방식이 검색 정확도의 병목이었습니다:
- 스벅 / 스타벅스 / Starbucks
- 넷플 / 넷플릭스
- 베라 / 베스킨라빈스
이를 해결하기 위해:
- 도메인 특화 동의어·줄임말 사전 구축
- LLM 기반 질의 정규화 (사용자 표현 → 데이터 표현 자동 변환)
- Query Expansion으로 의미 단위 검색 확장
아키텍처
사용자 질문
↓
에이전트 (LangGraph ReAct)
├── Tool 호출 필요 여부 판단
├── query_extraction (활동·시간 관련 내용 추출)
├── GraphRetriever
│ ├── 벡터 검색 (ChromaDB)
│ └── 그래프 탐색 (메타데이터 엣지)
└── 검색 결과 종합
↓
최종 답변 반환
기술 스택:
- 에이전트: LangGraph ReAct Agent
- 벡터 저장소: ChromaDB
- 검색: 벡터 검색 + 그래프 탐색 하이브리드
- 프론트엔드: LangGraph Studio 연동
서비스 화면
성과
- 정확도 92%: 사용자 요구사항 기반 평가셋 80개 중 74개 정답
- Context 85% 감소: 20,000개 → 3,000개
- 복합 질의 검색 가능: "캠핑에서 사용한 버너 브랜드" 같은 관계 추론
- 맥락 의존적 검색: 단순 유사도 기반 검색 대비 품질 향상
회고
잘한 점
- 그래프 구조 도입 결정: 초기에 "벡터 검색만으로 충분하지 않을까?"라는 의견이 있었지만, 복합 질의 테스트 결과를 근거로 그래프 도입을 결정한 것이 프로젝트 성공의 핵심이었습니다.
- Context 최적화: "더 많은 정보 = 더 좋은 답변"이라는 직관을 데이터로 반증하고, 과감하게 85% 줄인 결정이 옳았습니다.
- 평가셋 기반 개발: 사용자 요구사항에서 직접 평가셋을 만들어 개발 방향을 잡은 것이 효과적이었습니다.
배운 점
- 라이프로그 데이터는 "관계"가 핵심입니다. 개별 이벤트의 유사도보다 이벤트 간 연결 구조가 검색 품질을 결정합니다.
- 한국어 NLP는 여전히 도전적입니다. 줄임말/외래어 처리는 사전 구축만으로는 한계가 있으며, LLM 기반 정규화가 필수적입니다.
- Context 양과 답변 품질은 비례하지 않습니다. 노이즈 제거가 곧 성능 향상입니다.