IBK캐피탈 AI 여신 승인신청서 자동화 시스템 구축기
TL;DR
IBK캐피탈의 승인신청서 작성 소요시간을 3.5일에서 1일 이내로 약 70% 단축하고, 반복문서 자동화를 통해 연간 약 4.7억 원 절감 효과를 달성한 AI PoC 프로젝트입니다. 완전폐쇄망(On-Prem) 환경에서 RAG 파이프라인을 구축하며, Table-First 파싱 전략과 HeadingRefiner 기반 청킹으로 금융 문서의 수치 정확성 문제를 해결했습니다.
프로젝트 배경
승인신청서는 IBK캐피탈 영업점이 기업고객과 상담 후 작성하는 비정형 문서입니다. 사업보고서, 감사보고서, 재무제표 등 다양한 문서를 참조하여 9개 섹션을 채워야 하며, 작성과 검토에 많은 시간과 인력이 소요됩니다.
핵심 과제: 생성형 AI 기반 자동화를 통해 문서 작성 효율성과 정확성을 동시에 높이는 것. 특히 완전폐쇄망 환경이라는 제약이 있었습니다.
기술적 도전과 해결
1. 문서 전처리 파이프라인: Table-First 전략
금융 문서에서 가장 중요한 건 수치의 정확성입니다. 단순 PDF 텍스트 추출로는 표 데이터가 깨지는 문제가 있었습니다.
우리가 세운 3가지 원칙:
- 정확한 수치 보존 — 재무제표의 숫자 하나가 틀리면 전체 신뢰도가 무너짐
- 문서 내 의미 단락을 정확히 추출 — 섹션별로 올바른 컨텍스트를 전달해야 함
- 근거 기반 의견 생성 — 출처가 명확한 답변이 필수
이를 위해 Table-First Approach를 채택했습니다:
- Table 문서를 우선 처리 — 표 구조가 수치 왜곡이 가장 적음
- 일반 PDF 텍스트는 fallback으로 보완
- OCR은 최후 수단으로만 사용
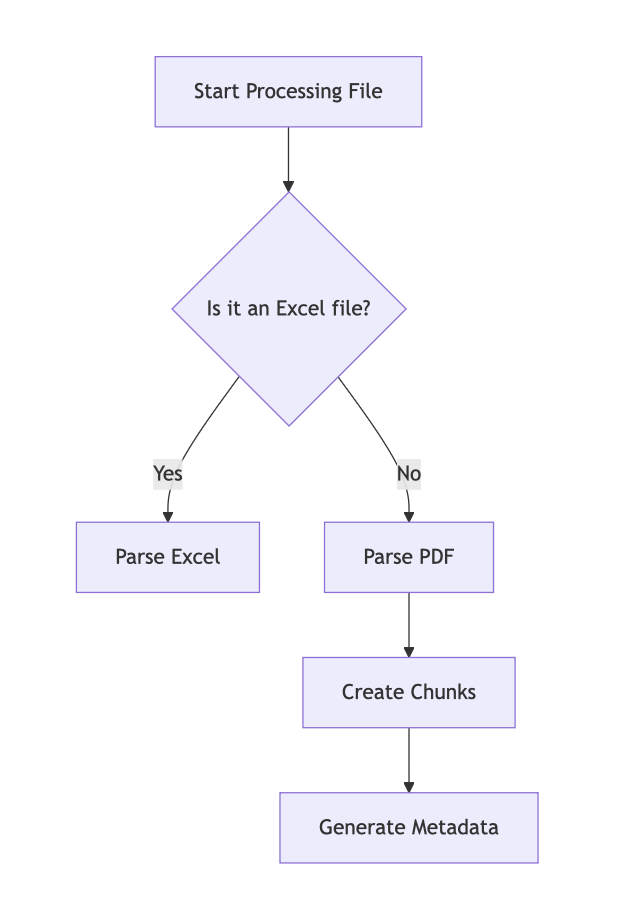
전체 종합 처리 플로우는 다음과 같습니다:
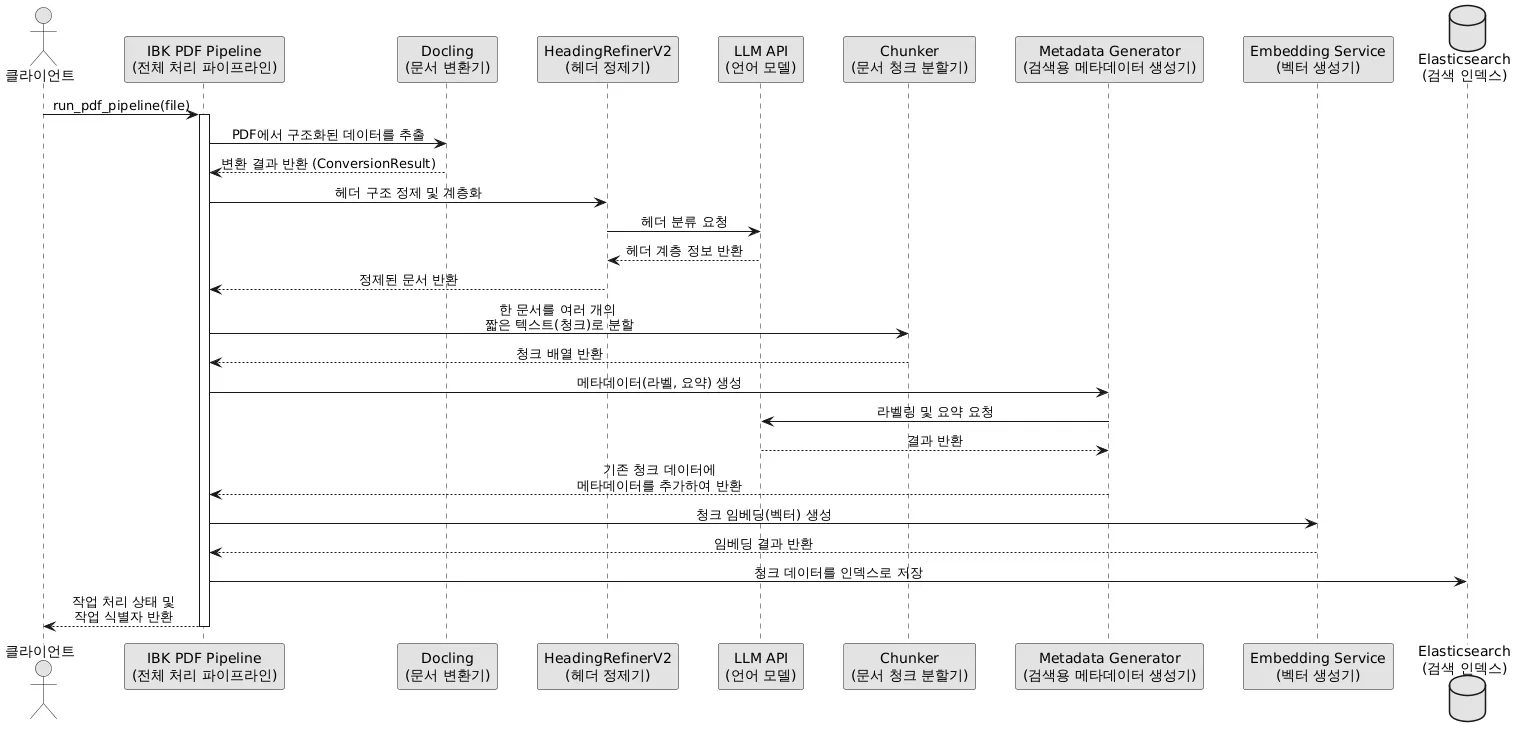
2. HeadingRefiner: 의미 단락 분리의 핵심
청킹(Chunking) 품질은 heading 추출의 정확도에 직결됩니다. 이를 위해 HeadingRefiner 모듈을 설계했습니다:
- 목차가 있는 문서: 목차 기반으로 계층 구조를 자동 구성 → LLM 호출 최소화
- 목차가 없는 문서: LLM을 활용하여 heading 계층을 재구성
이 접근법으로 의미 단락을 더 정확하게 분리할 수 있었고, 최종적으로 의견 생성 품질이 크게 향상되었습니다.
3. 비동기 + 병렬처리로 소요시간 54% 단축
초기 파이프라인은 문서 하나를 처리하는 데 12분 41초가 걸렸습니다. 두 가지 최적화를 동시에 적용했습니다:
- Heading 정제 및 메타데이터 생성 과정을 비동기 처리
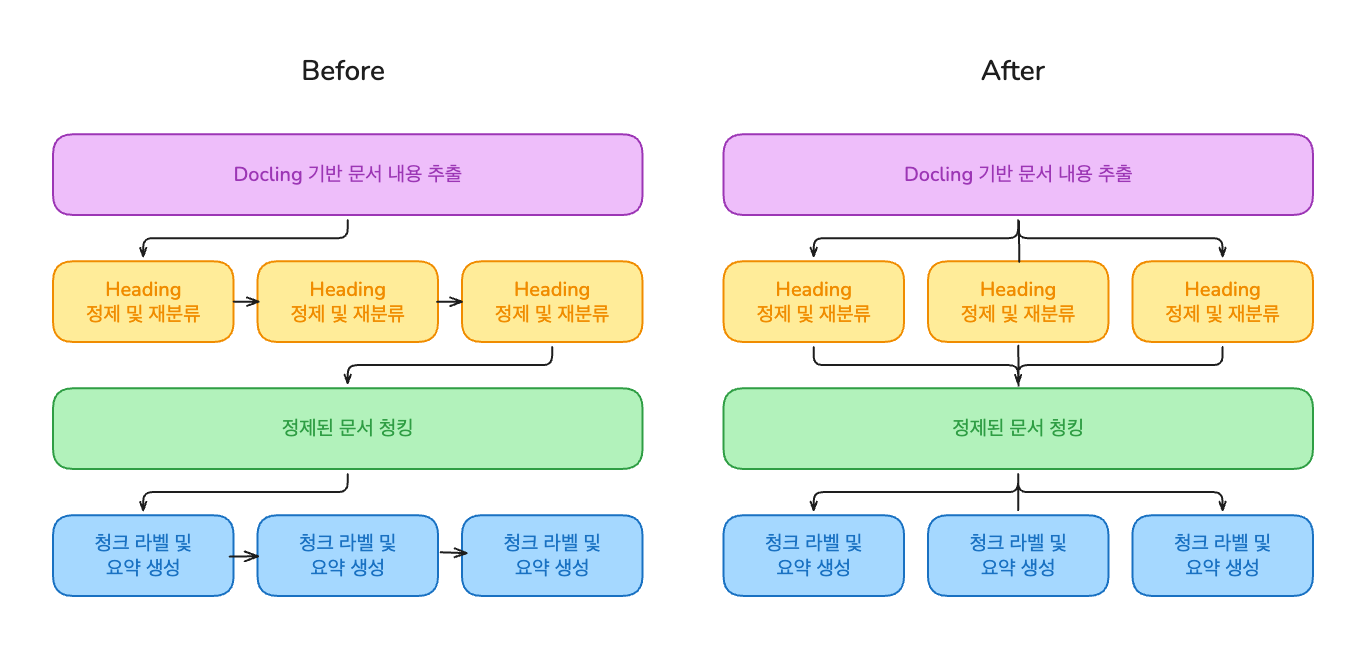
- 다중 Worker 기반 병렬 처리
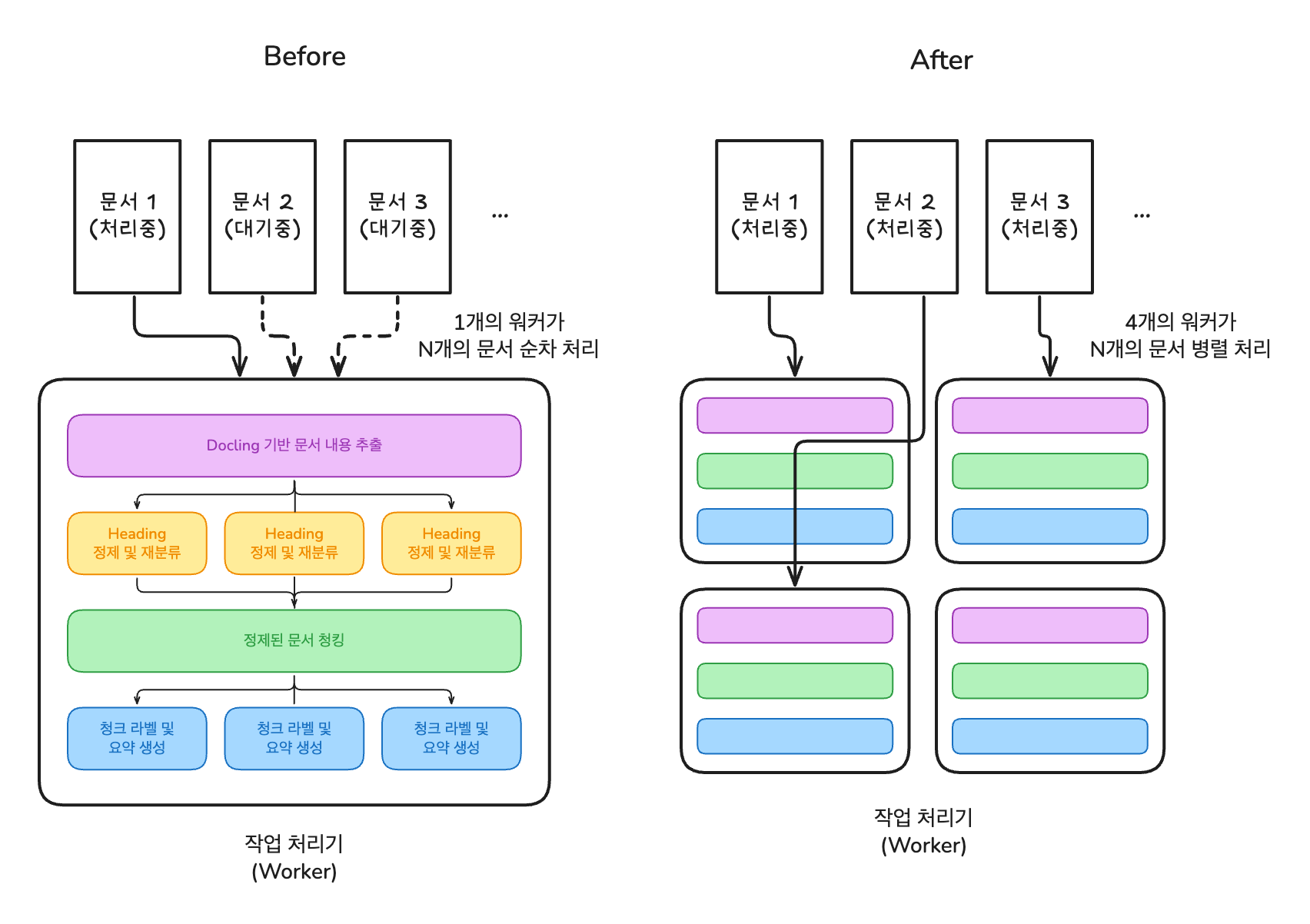
결과: 12분 41초 → 5분 54초 (약 54% 단축)
4. RAG 파이프라인: Tabular 데이터의 정보 손실 최소화
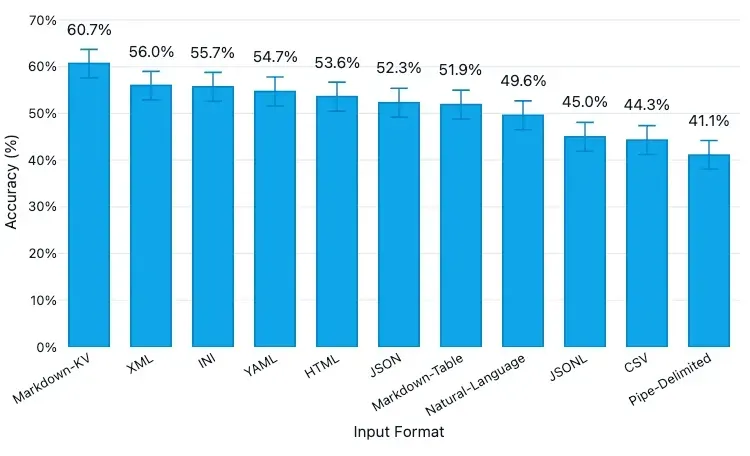
전처리된 PDF에서 추출된 표 데이터는 형태가 가변적입니다. LLM이 이를 해석할 때 정보 손실을 최소화하기 위해, 컨텍스트로 활용되는 데이터 형태를 Markdown KV(Key-Value) 구조로 변환하여 적용했습니다.
Prompt Engineering을 통해 승인신청서 내부 9개 Section에 대한 개별 응답을 생성하도록 최적화했습니다.
기술 스택
| 항목 | 상세 |
|---|---|
| Web Client | Next.js |
| Backend Server | FastAPI |
| Database | Elasticsearch, Redis |
| 환경 | On-Prem (완전폐쇄망) |
성과
- 작성 소요시간 약 70% 단축: 기존 3.5일 → 1일 이내
- 자동작성으로 생산성 23%p 향상
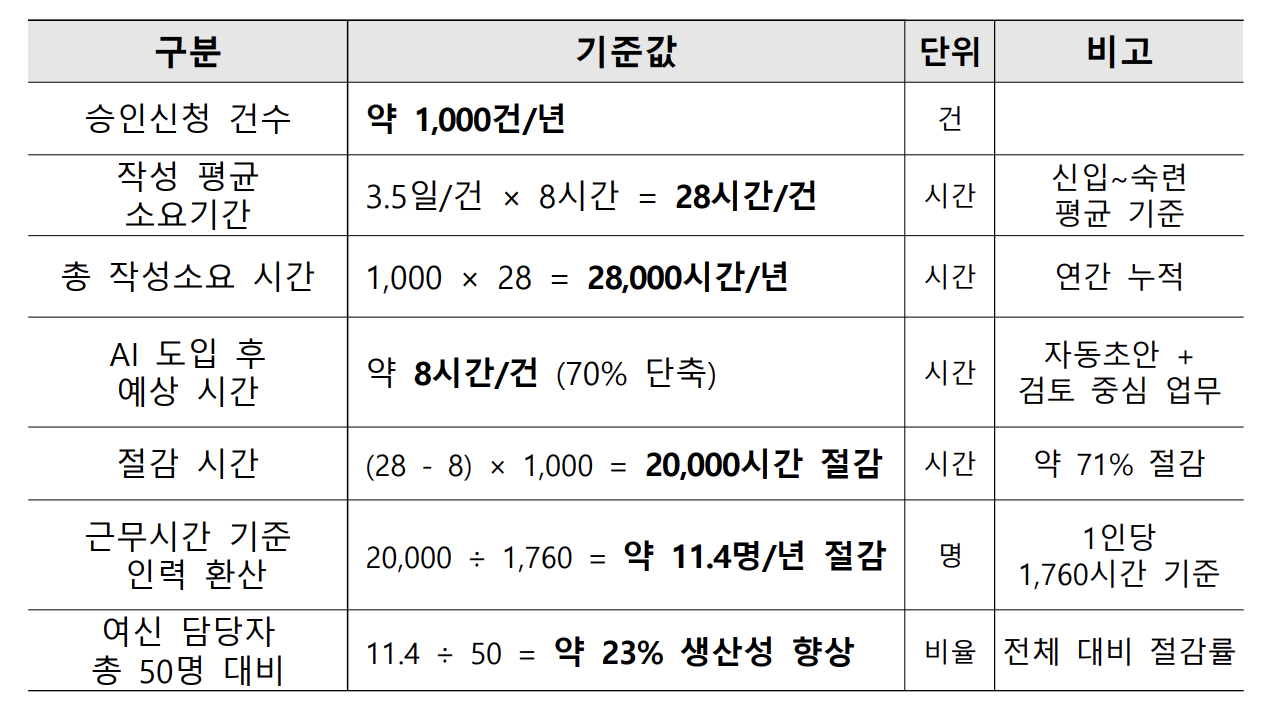
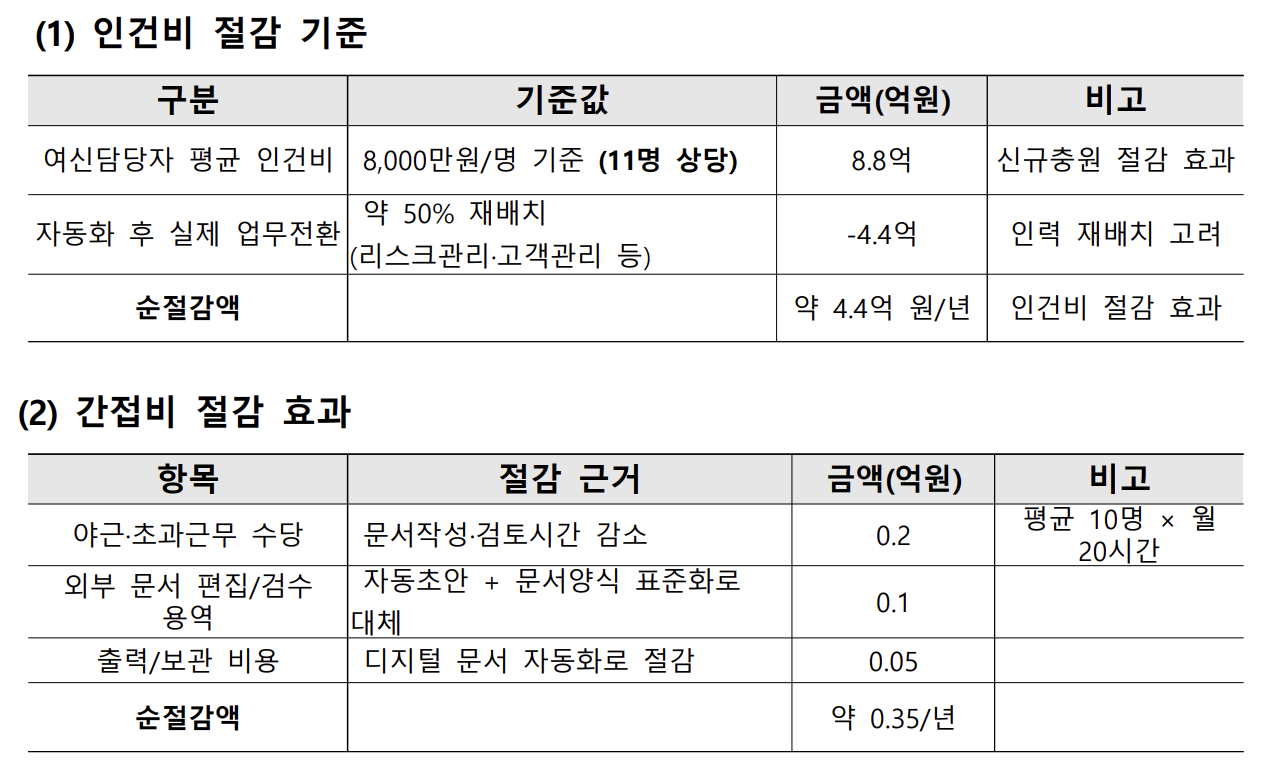
- 연간 약 4.7억 원 인건비 절감 효과
- 내부 실무자 만족도 약 80% 달성
- 정성점수: 79.41/100
- 평균 만족도: 4/5
회고
잘한 점
- Table-First 전략: 금융 도메인의 핵심인 수치 정확성을 최우선으로 놓은 것이 프로젝트 성공의 열쇠였습니다.
- HeadingRefiner의 이중 전략: 목차 유무에 따라 분기하는 설계가 다양한 문서 유형에 대한 범용성을 확보해줬습니다.
- On-Prem 환경 대응: 클라우드 서비스 의존 없이 완전폐쇄망에서 동작하는 아키텍처를 구축한 경험은 향후 프로젝트에도 큰 자산이 됩니다.
배운 점
- 금융 문서에서 LLM의 역할은 "생성"보다 "정확한 정보 추출과 구조화"에 더 가깝습니다. Prompt Engineering의 방향도 이에 맞춰야 합니다.
- 비동기/병렬 처리는 초기부터 설계에 반영해야 합니다. 나중에 추가하면 아키텍처 변경 비용이 큽니다.
- 실무자 피드백 기반의 정성 평가는 PoC 단계에서 본사업 전환을 위한 중요한 근거가 됩니다.