vLLM Korea Meetup 참석 후기: Production-Level LLM 서빙의 현주소

TL;DR
vLLM Korea Meetup에 참석하여 LLM 서빙이 "좋은 모델을 띄우는 것"에서 **"클러스터 레벨에서 효율적으로 서빙하는 것"**으로 패러다임이 이동하고 있음을 체감했습니다. Production Stack(스퀴즈비츠), CXL 기반 KV Cache 공유(XCENA), On-Prem GPU 서빙(삼성전자), 오픈소스 모델 공개 노하우(Upstage), HyperCLOVAX 서빙기(네이버클라우드) 등 실전 경험을 들을 수 있었고, 특히 KV Cache 관리가 서빙 성능의 핵심 병목이라는 점이 모든 세션을 관통하는 키워드였습니다.
컨퍼런스 개요
- 행사명: vLLM Korea Meetup (2nd)
- 일시: 2026년 4월 2일 18:00~22:00
- 장소: 오프라인 (메인홀 + 멀티룸 트랙)
- 주요 테마: vLLM 기반 Production-Level LLM 서빙
- 스폰서: 리벨리온, 스퀴즈비츠

트랙 구성:
| 시간 | Track 1: vLLM with Open Source | Track 2: vLLM in Business |
|---|---|---|
| 19:00-19:30 | vLLM overall update (리벨리온, 레드햇) | - |
| 19:30-20:00 | vLLM Production Stack (스퀴즈비츠) | - |
| 20:20-20:50 | LMCache & CXL 통합 여정 (XCENA) | 온프레미스 GPU x vLLM 서빙기 (삼성전자) |
| 21:00-21:30 | 오픈소스 모델 공개하기 with vLLM (Upstage) | HyperCLOVAX 옴니 모델 서빙기 (네이버클라우드) |
인상 깊었던 세션
1. vLLM Overall Update (리벨리온 + 레드햇)
- 핵심 메시지: 지난 6개월간 vLLM 코어에 대규모 변화가 있었으며, v0에서 v1으로의 전환이 완전히 완료됨
- 주요 업데이트:
- v0 deprecation 완료 (v0.11.0, 2025년 10월) — 디폴트 엔진을 v1으로 전환하고 v0 완전 제거
- Async Scheduling 도입 — 스케줄링과 실행을 비동기적으로 분리하여 성능 향상
- Model Runner V2 — 코어 컴포넌트 재설계로 연산·메모리 효율성 개선
- 리벨리온 업데이트: PyTorch 2.0 네이티브 지원으로 NPU 통합 강화, PyTorch RBLN 4월 10일 오픈 예정, Rebel 100 신제품 출시 (H200급 성능)
- Red Hat 업데이트: vLLM 0.18.2 릴리스, Semantic Router v0.2, GuideLLM(벤치마킹 도구), vLLM-Playground(개발 환경)
- 시사점: vLLM의 코어 아키텍처가 성숙 단계에 접어들면서, 이제는 에코시스템(Production Stack, Semantic Router 등)으로 관심이 이동하고 있음
2. vLLM Production Stack (스퀴즈비츠 김태수 CTO)
- 핵심 메시지: 단일 vLLM 인스턴스만으로는 production-level 서빙이 불가능. Request Router + Shared KV Cache를 얹어야 클러스터 레벨 성능 확보 가능

- 3 Layer 아키텍처:
- Inference Amplification: vLLM 엔진의 코어 성능 (PagedAttention 등)
- Platform Layer: Observability, 쉬운 배포, Auto-scaling
- System Intelligence: Semantic Router를 통한 intelligent routing

- Router가 핵심: Round-robin이 아닌 prefix-aware, KV cache-aware, disaggregation-aware한 전략적 라우팅

- Cluster-level Cache Reuse: LMCache를 통해 다양한 tier storage 지원, Long context에서 prefix 재사용으로 TTFT 극적 단축

- Observability: Jaeger + OpenTelemetry 기반 트레이싱, W3C Propagation 지원 (v0.1.9~), 사전 정의된 대시보드 제공
- Auto-scaling: CPU/GPU 사용량이 아닌 inference-specific metrics(queue depth, latency) 기반
- 성능: 캐시 활용 시 3
10배 latency 개선, 23배 throughput 향상 (런칭 블로그 기준)

- 시사점: "모델이 아무리 좋아도 serving quality가 중요하다"는 메시지가 인상적. 우리 팀도 단일 인스턴스를 넘어 클러스터 레벨 서빙을 고려할 시점이 올 수 있음
3. LMCache & CXL 통합 여정 (XCENA 이주호님)
-
핵심 메시지: KV Cache의 2대 과제는 "용량이 너무 크다"와 "빠르게 전송해야 한다". CXL이 이 두 가지를 동시에 해결할 수 있는 기술
-
KV Cache 규모감:
- 70B 모델, 128K context → 40GB
- 5M context → 320GB
- 클로드/GPT 급 서비스에서는 500GB 이상 추정
-
CXL이란: PCIe 슬롯을 통해 DRAM을 확장하고, 여러 서버가 동일한 메모리에 나노초 레이턴시로 직접 접근(load/store)할 수 있는 프로토콜
-
Maru: XCENA가 개발한 CXL 기반 KV Cache 스토리지 엔진 오픈소스 (GitHub)
- LMCache에 스토리지 백엔드로 통합
- 네트워크 전송 없이 메모리 주소만 공유하여 KV Cache 공유
- 벤치마크: CXL 백엔드가 TCP 기반 P2P 대비 우수한 TTFT 성능
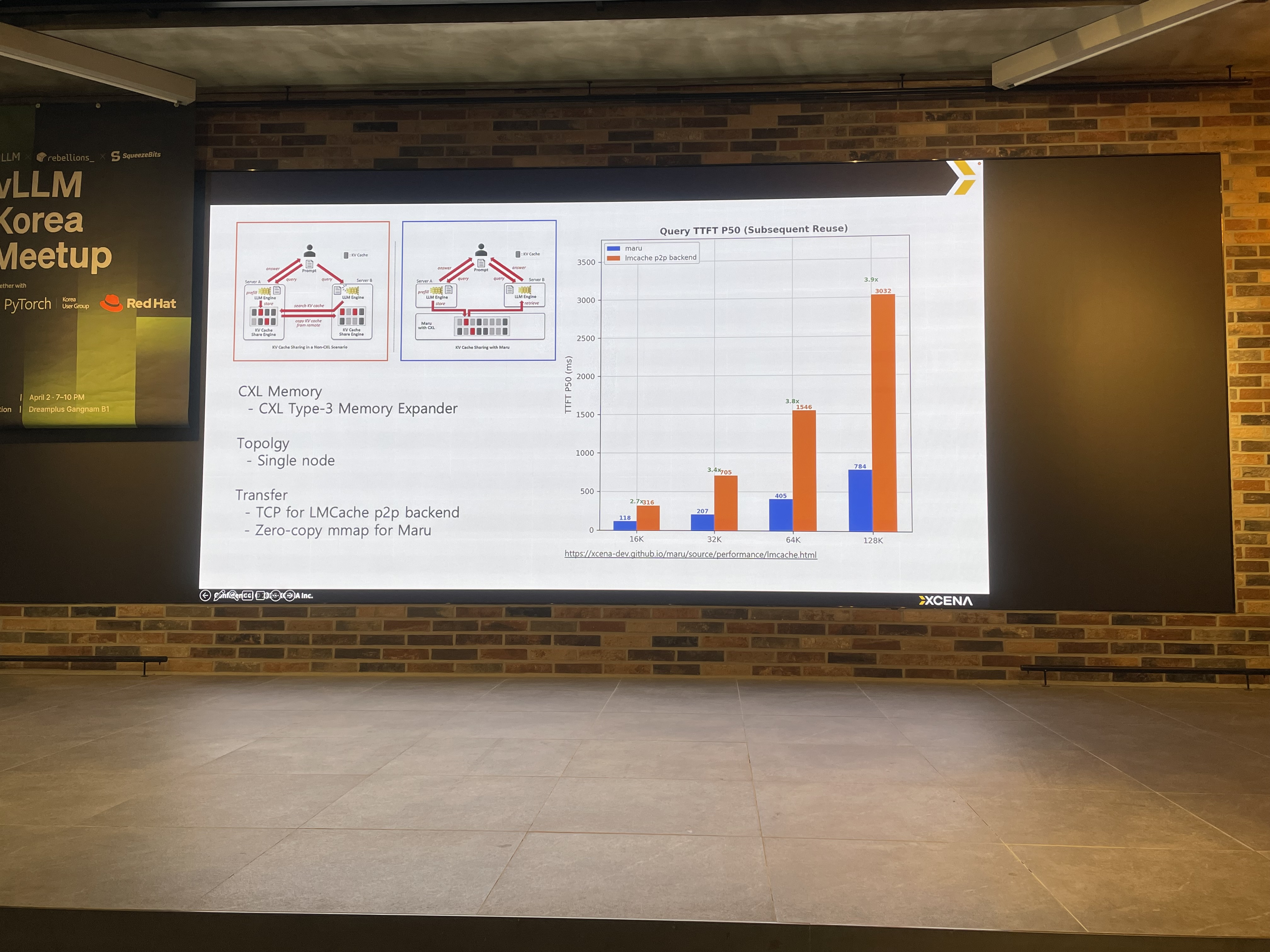
- 시사점: CXL은 아직 에코시스템이 초기 단계(스위치 비용 높음)이지만, KV Cache 공유 문제의 근본적 해결책이 될 수 있음. VectorDB에서도 CXL 활용 사례가 늘고 있다고 하니 주시할 필요 있음
업계 트렌드 & 시사점
- "좋은 모델" → "좋은 서빙"으로 관심 이동: 작년까지는 모델 성능이 화두였지만, 올해는 서빙 품질(latency, throughput, scale-out)이 핵심 키워드
- KV Cache가 모든 세션을 관통하는 주제: Cache 압축(KV-Compress), Cache 공유(LMCache), Cache 저장(CXL) 등 다양한 레이어에서 연구 활발
- Kubernetes 네이티브 inference: Gateway Inference Extension, CRDs 등 K8s 생태계와의 깊은 통합이 진행 중
- PD Disaggregation 확산: Prefill과 Decode를 분리하는 아키텍처가 production 환경에서 실질적으로 도입되기 시작
- Observability의 중요성: 대규모 서빙에서 모니터링/메트릭 수집이 "있으면 좋은 것"에서 "필수"로 격상
팀 적용 포인트
- LMCache 스터디: Prompt Caching 전략을 이미 다루고 있으니, LMCache를 통한 클러스터 레벨 KV Cache 공유 방안 검토
- Production Stack 테스트: 멀티 인스턴스 서빙이 필요한 시점에 vLLM Production Stack을 레퍼런스로 활용 가능. Helm Chart로 빠르게 PoC 가능
- Inference 메트릭 기반 Auto-scaling: GPU 사용률이 아닌 queue depth, latency 기반 스케일링 방식을 On-Prem 프로젝트에 적용 검토
- CXL 동향 모니터링: 당장 적용은 어렵지만, VectorDB + CXL 조합은 우리 RAG 파이프라인과 직결되는 주제. Maru 프로젝트 워치
전체 후기
vLLM을 production level에서 실제로 사용해본 경험이 없어서 구체적으로 고민해본 적은 없었는데, 실제 서비스 단계에서 사용하려면 단순히 좋은 모델이 있는 것을 넘어서 latency를 줄이고 throughput도 고려하면서 효율적으로 좋은 성능을 내기 위한 노력이 필요하다는 것을 알게 되었다.
K8s, Helm, CXL, NPU, DRAM 등 인프라/하드웨어 레벨의 내용도 많이 등장해서 공부할 게 많다는 생각이 들었다.










